 I'm a tech professional (ex-Amazon) with experience including software engineering, and management. Currently living in NYC.
I'm a tech professional (ex-Amazon) with experience including software engineering, and management. Currently living in NYC. Building a music app with ReactJS, Lambda, S3 and the Spotify API

What is AOTW?
AOTW is the name of a music app I built with ReactJS and AWS Lambda. It stands for Albums of the Week, which is also the name of a shared playlist my friends and I update weekly. We put albums in that shared playlist and throughout the week we all listen and discuss them. Come sunday evening, I manually clear the playlist so we can start fresh on Monday (yes I borrowed that mechanic from Spotify’s own Discover Weekly).
I wanted to create a webapp that pulled albums from that shared playlist and rendered them on a webpage. The app had to have a clean UI with album covers, and an easy way to play those albums right from the app. Another feature was to replicate the functionality of the open source project called Spotispy, which nicely displayed fullscreen album art suitable to grace a TV screen while the album played.
Architecture overview
AOTW is a severless webapp hosted on S3 and built with ReactJS. It sends requests to API Gateway which takes care of routing those requests to a Lambda function. The Lambda function reads the contents of that shared Spotify playlist (which was pulled using the Spotify API) and returns them to the front-end. Here’s a diagram…
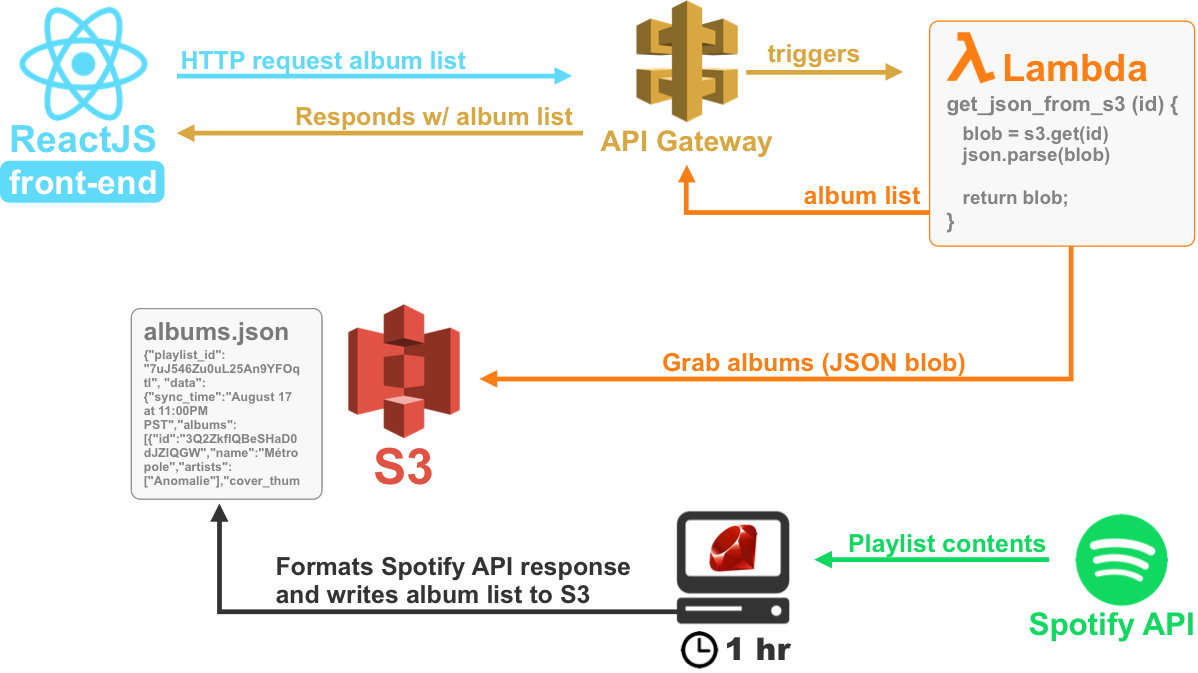
As you can see from the diagram above, my description simplified a few things. I’ll go more in depth below, but since the Spotify API required periodic authentication – I didn’t want users to go through the hassle of creating an account then authenticating with Spotify – I opted to connect to the Spotify API using my own credentials. I wrote a Ruby script which interacts with the Spotify API, and writes a JSON blob S3. My Lambda function just parses that S3 file (yes I know this is a hacky solution, what can you do).
The Spotify API
The Spotify API allows you to perform a bunch of operations related to querying data about albums/artists/songs as well as user specific data (like playlist contents). Since Spotify requires an access token to make API calls, I couldn’t just hardcode a token then have the front-end directly contact the Spotify API; remember the whole webapp is just static JS. The correct way to fullfill this requirement would be to have users go through an authorization flow, then link their Spotify account; however, this means I’d need to somehow build that auth flow with Lambda functions and store their credentials, or spin up my own server. Neither of those things sounded like fun, plus I wanted to keep the whole webapp “serverless”.
What I ended up doing was writing a Ruby script which used my Spotify client credentials to generate an auth token specific to my account. I could then use that auth token to generate API access tokens. With these access tokens I was free to make Spotify API calls.
With auth taken care of, I wrote a ruby script which calls the Spotify API’s /playlists endpoint to get the contents of our shared playlist, parse out the albums and write them to a JSON file. The script then uses AWS’s resources sdk to upload that JSON file to S3. The Ruby script itself is hosted on my private EC2 box and is run hourly by a cron job. So, in essence, we have a JSON blob in S3 that is updated hourly with the contents of our shared Spotify playlist. When somebody adds an album to that playlist, within an hour, it is appended to that JSON blob in S3.
Lambda & API Gateway
AWS Lambda is a neat service that allows you to write code in a variety of languages that is triggered by events. You don’t manage the servers that the code runs on, and you can write your functions in the browser. There is a nice little video on Lamda’s homepage which explains this more in depth.
The next piece of the puzzle for the AOTW webapp was to write a Lambda function which takes a playlist ID, and looks for the corresponding JSON blob in S3. Here is pseduo code of what that lambda function looks like…
exports.handler = (event, context, callback) => {
# Grab the playlist_id from the request path (sent by API Gateway)
playlist_id = event.pathParams.playlist_id
# Grab the albums from the playlist file in S3
albums_blob = s3.getObject({ Bucket: 'aotw', key: playlist_id })
# Use the 'callback' function to return an http response that
# will be proxied through to the user by API Gateway
callback({
statusCode: 200,
headers: {...},
body: `{ playlist_id: playlist_id, data: album_blob.Body.toString() }`
})
}Now wait a second, if you’re thinking
Jack why *smh*. If you cut corners and used a cron job to upload a list of albums to S3, why not just skip Lambda all together and grab that file directly from S3?!
Two reasons.
1) I didn’t plan on keeping around the cron job –> S3 flow, it doesn’t scale and is overall pretty hacky. This way I can hotswap in something better without changes to front-end code.
2) A motivator for starting this project in the first place was to learn/use Lambda
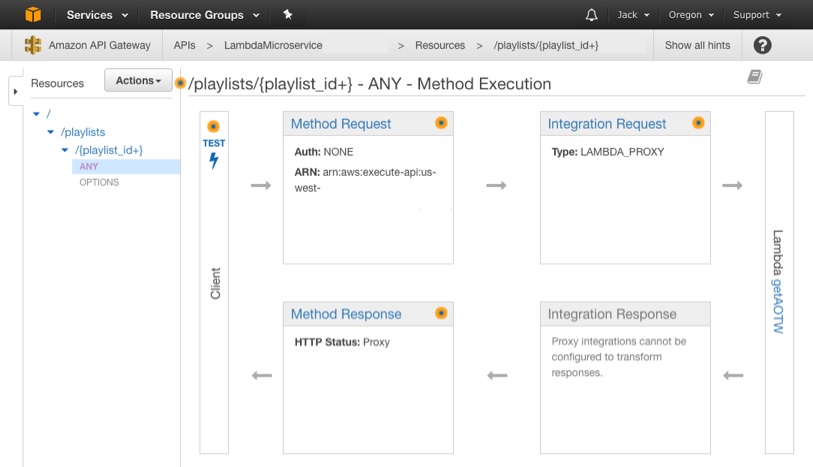
Lambda functions cannot be called directly over the public internet, they are just code functions which take input and return output. Knowing this, we need a way to trigger the Lambda function so we can call it from our front-end. API Gateway was the solution here as it handles accepting/processing API calls and, crucially, allows these HTTP requests to trigger Lambda functions.
I setup a basic API with one endpoint. That endpoint accepts a playlist ID parameter and triggers the Lambda function. It then takes the output of the Lambda function (which is a JSON list of albums) and returns it to the requester.
ReactJS
I’m not going to go in depth about React in this post, but suffice to say it is a front-end JS framework for writing webapps, and I enjoy working with it. The key point for this webapp is that React can be complied to static HTML/CSS/JS files. Since these are all static, they can be hosted and served by S3. Add a global CDN on top of those static assets and you’ve got a wicked fast webapp with a API backend and no need to deal with servers.
Conclusions
I started this project as a way to experiment with Lambda and “serverless” computing, to see how it stacks up. If it could be a viable alternative to something like a Rails server. I did learn quite a bit in the process and all told, this sort of architecture points to an interesting future in cloud computing. I’m not thinking it’ll be replacing large scale APIs anytime soon, especially those with complex data models, but for now I’ll keep poking around at it because it’s pretty fun.